How LLMs Work
Build an intuition-first understanding of Large Language Models. Follow Nina, a product engineer, from the physical "two-file" reality through training, scaling, and the limits of what models can do on their own.
Why take this course?
A radically transparent demystification of AI. Strip away the hype and explore the anatomy, evolution, and limits of modern LLMs through direct analogies, visual models, and a hands-on engineering narrative.
Course Modules
Start from what you already know — you've used ChatGPT or Claude. Then trace the arc from counting words (Bag-of-Words) to meaning vectors (Word2Vec) to contextual attention to the Transformer breakthrough — and understand why decoder-only models like GPT became the LLMs we know today.
Learning Goals
- Ground your understanding of what an LLM does from the outside: text in, text out, token by token.
- Explain why computers need numbers to process language, and how each approach solved the failures of the last.
- Describe the Bag-of-Words model, its strengths, and its critical limitations.
- Understand how embeddings encode meaning as vectors, and how attention makes them context-dependent.
- Understand how the Transformer solved the sequential bottleneck of RNNs.
- Distinguish encoder-only (BERT) from decoder-only (GPT) Transformers and when each is appropriate.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.
What an LLM Does
Nina ships her first LLM feature in a weekend. It answers questions, summarizes docs, writes code. Then a user asks: "Wh…

From Word Counts to Meaning Vectors
Before 2013, computers represented language by counting words. "Bank" plus "loan" meant finance. "Bank" plus "river" mea…
Attention → Transformer → Scale
Word2Vec gave "bank" one fixed vector — same whether it sits next to "river" or "deposit." Real language doesn't work th…
Follow Nina as she discovers that an LLM is just two files: a 140GB parameters file and 500 lines of C code. Understand inference, the 100x compression ratio, and why the model is a black box you cannot debug by reading code.
Learning Goals
- Explain the physical model of an LLM: a parameters file and a run file.
- Describe inference as a loop of next-token prediction.
- Understand hallucination as a consequence of lossy compression, not a software bug.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.

Two Files, One Compression
Behind every LLM API call sits something surprisingly simple: two files.
The parameters file (~140GB) is billio…
Inference: Token by Token
Every response is a loop, not a paragraph generator. The run file scores all ~50K vocabulary tokens against the prompt a…
Temperature
Same prompt, different answer every time. That's not random — it's temperature: a parameter that controls how much t…
Trace the evolution from an internet "dreamer" to a polished assistant. Understand the three stages — Pre-training (lossy compression), Fine-tuning (behavioral formatting), and RLHF (human preference polish) — and why alignment improves tone but not accuracy.
Learning Goals
- Explain Pre-training as lossy compression of the internet into a base model.
- Describe how Fine-tuning and RLHF transform a dreamer into a helpful assistant.
- Recognize the alignment tax: fluent delivery does not equal factual accuracy.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.

Base Models Complete Patterns
Nina downloads an open-source base model and asks: "What is the best way to handle database migrations?" Instead of answ…
Pre-training Creates the Dreamer
Pre-training is the expensive stage. A cluster of thousands of GPUs processes roughly 10TB of internet text with one obj…
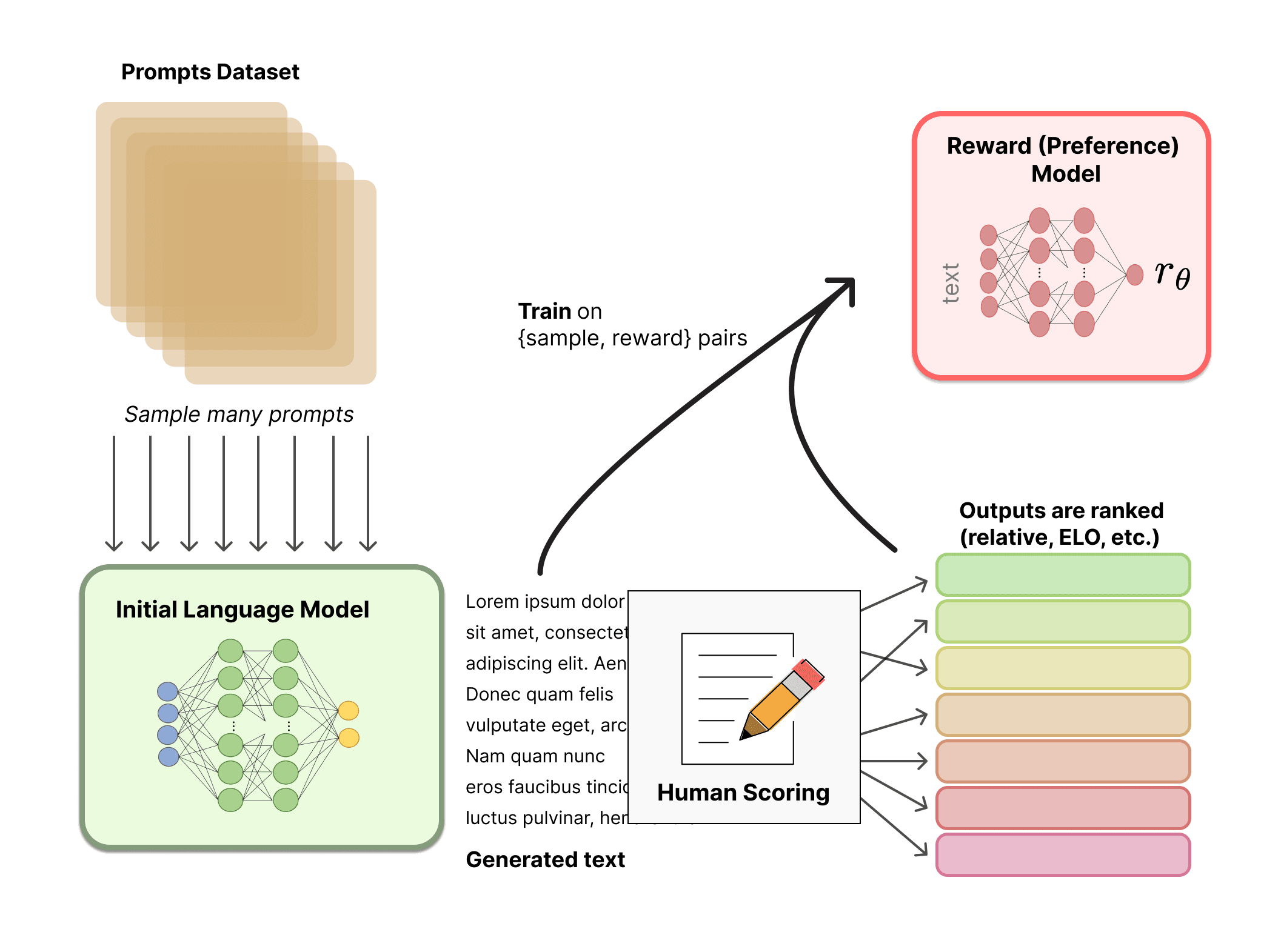
SFT and RLHF Create the Assistant
Fine-tuning changes the interface, not the knowledge. Supervised Fine-Tuning (SFT) shows the base model tens of thou…
Discover why scaling laws drive the compute arms race, and why bigger models still can't do math. Understand what scaling fixes (general capability) and what it doesn't (arithmetic, real-time data, hallucination) — setting up the architectural patterns you'll learn in later courses.
Learning Goals
- Understand scaling laws as a predictable investment curve for general capability.
- Distinguish between general capability gaps (scaling helps) and architectural gaps (scaling alone cannot fix).
- Recognize that arithmetic, real-time data, and hallucination require architectural solutions beyond scaling.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.

Exactness Is Not a Scaling Problem
Nina's instruct model handles text queries cleanly. Then a customer asks: "What's my prorated refund if I cancel 17 days…
What Scaling Actually Buys
Scaling laws explain the GPU arms race. In 2020, OpenAI researchers found smooth power-law relationships between compute…
Capability Gaps vs Architectural Gaps
A capability gap is something the model can plausibly learn to do better: understand a vague request, follow a stric…
Consolidate the four mental models into a practical builder's toolkit. Learn three rules for production LLMs, and chart your path to the next courses in the roadmap.
Learning Goals
- Synthesize the four core mental models (the arc, two-file reality, training pipeline, scaling & limits) into a unified toolkit.
- Apply three production rules: never trust the model's memory, math, or confidence.
- Identify which advanced topics (tokens & embeddings, prompt engineering, RAG, agents) address which gaps.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.
Three Rules for Building with LLMs
The course reduces to three production rules.
Never trust the model's memory. Parameters are lossy compression of t…

Nina Ships the System
Nina returns to her VP with a different answer than she expected.
An LLM is not a magic database, calculator, or truth…
What Each Next Course Solves
Each next course fills one architectural gap.
Prompt Engineering constrains the model's freedom: clearer instructio…
Step back and see the bigger pattern: the LLM as an operating system. Map components to OS concepts (CPU, RAM, I/O), learn System 1 vs System 2 thinking modes, and build a systematic debug playbook for production AI systems.
Learning Goals
- Map LLM architecture to OS concepts: model as CPU, context window as RAM, tools as I/O.
- Distinguish System 1 (constant compute, fast) from System 2 (deliberative, reasoning) thinking modes.
- Apply a systematic debug playbook: stage fit, prompt fit, context fit, decoding fit, model fit.
Concept Card Preview
Visuals, diagrams, and micro-interactions you'll see in this module.
The LLM Operating System
Nina sketches her system on a whiteboard: model in the center, context window feeding it, tools around the edges, compre…
Context Management Is Memory Management
Every token in the context window has a cost. System instructions compete with conversation history. History competes wi…
Fast Thinking, Slow Thinking, Tools
Standard LLM calls spend roughly the same compute per generated token whether the task is a greeting or a refund-policy…